

8美元即可对DeepSeek-V3.2做强化学习?腾讯优图提出Training-
大模型虽强,但在专业领域表现往往不尽如人意。常见的解决方案是通过监督微调或者强化学习更新模型参数,但这背后是高昂的代价与新的局限:
●泛化困境:通过参数微调优化的模型,往往泛化性不佳,只能胜任特定窄域任务。这导致企业不得不部署多个专用模型来覆盖完整业务需求,显著增加了系统复杂度和维护成本
针对上述挑战,腾讯优图实验室提出Training-Free GRPO方法,这种方法的核心思想是:不修改模型参数,而是通过反复积累和迭代“经验知识”来指导模型行为。Training-Free GRPO的提出,将强化学习在超大规模LLM及复杂Agent系统上的训练成为可能,启动了低成本、高效率的强化学习新时代。从此,强化学习不再是巨头的专属游戏deepseek,每个开发者的小业务都能用得起、用得好。

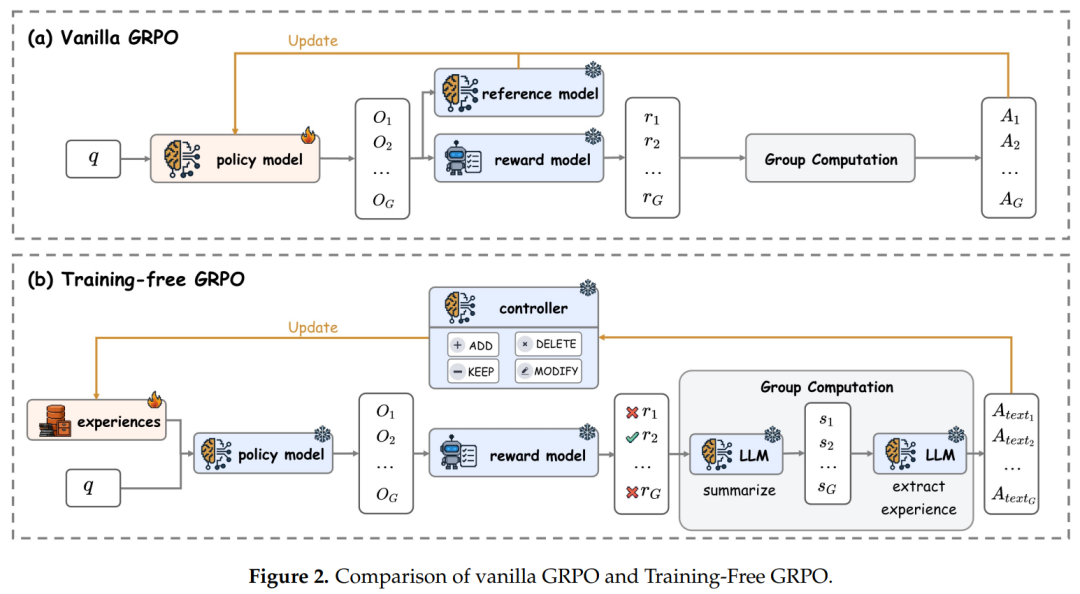
如图2所示,传统GRPO需要更新模型参数,而Training-Free GRPO冻结了模型参数,通过多轮强化学习不断更新优化经验库,在推理时注入学习到的经验知识,实现了零参数更新的强化学习效果。
如图3左侧所示,对于每个问题,模型会生成多个不同的解答路径。就像让学生用不同方法解同一道题,能够观察各种可能的解题思路。比如在数学题中,有的路径可能选择复杂的坐标几何法,有的可能发现更巧妙的几何性质法。这种多路径探索帮助我们发现最优策略。
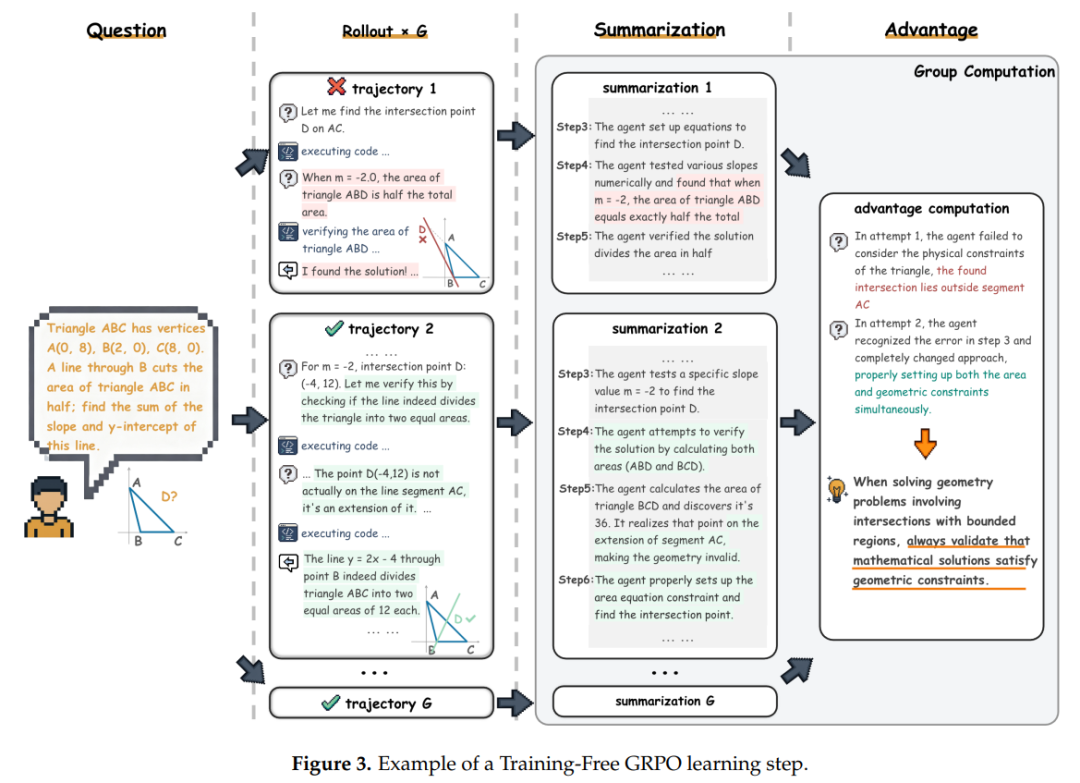
奖励只需提供少量样本及其参考答案,提供一个优化的方向即可。每个生成的解答都会获得一个客观评分。这个评分可以是:(1)与标准答案的匹配度;(2)代码执行结果的正确性;(3)网页搜索任务的成功率。
如图3右侧所示,模型会自我反思:比较同一组内的不同解答,总结出:“为什么A方法得分高?B方法哪里出错了?”。比如在案例中,模型发现:
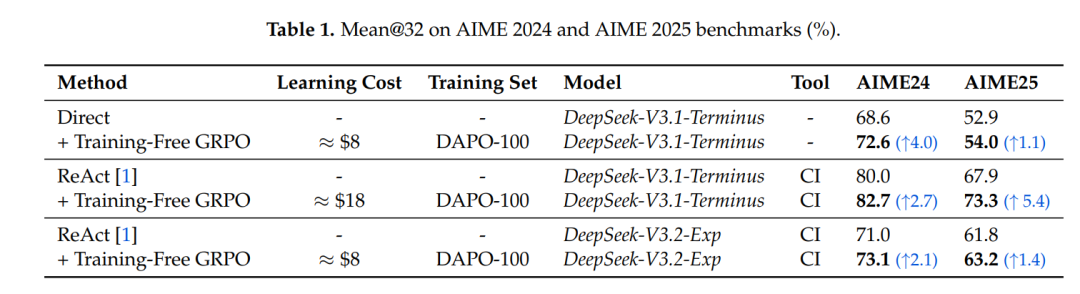
在数学推理上,仅用100个训练样本,花费约8-18美元,就能在已经足够强大的671B模型上继续提升性能。如表1所示,无论是否采用代码工具(CI,code interpreter)帮助解题,在AIME榜单上的Mean@32指标都能实现提升。
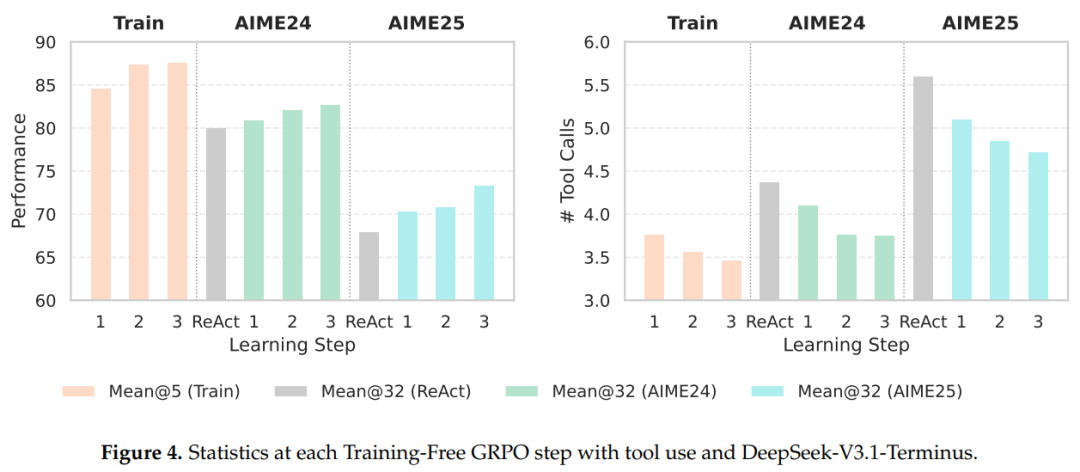
训练仅需要三个轮次,图4左侧子图中训练集Reward指标(橙色)和样本外AIME榜单上Mean@32指标(绿色和蓝色)都在稳步提升。右侧子图展现了训练中和样本外的平均工具调用次数均有所减少。这表明Training-Free GRPO 不仅能够鼓励正确的推理和行动,还能教会智能体找捷径,更高效明智地使用工具。

与传统强化学习(RL)方法相比,Training-Free GRPO实现了训练成本的数量级降低:
同时,对于大多数非密集调用型的实际应用,专门准备GPU提供训练好的32B模型推理服务也带来一定的固定成本。而Training-Free GRPO无论训练和推理都仅需API,随用随付!原文出处:8美元即可对DeepSeek-V3.2做强化学习?腾讯优图提出Training-Free GRPO,感谢原作者,侵权必删!

![[韩网翻译]Faker:战胜GEN让我们重拾信心,Guma五杀被抢感觉是遭报应了](http://deepseekw.cn/zb_users/upload/2025/07/20250731171855175395353567758.webp)