DeepSeek又回来了!国产大模型仍然能打!
发布之后,我曾一度觉得deepseek,国产大模型这下该着急了!因为,在算力不足的情况下,国产大模型似乎难以和国外大模型抗衡了!
据DeepSeek公众号介绍:官方网页端、App和API均已更新为正式版DeepSeek-V3.2。Speciale版本目前仅以临时API服务形式开放,以供社区评测与研究。
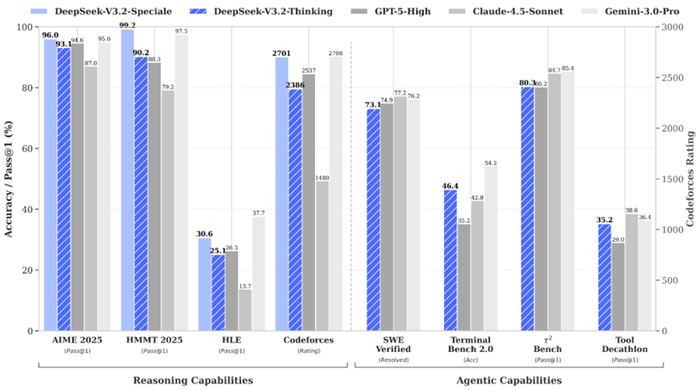
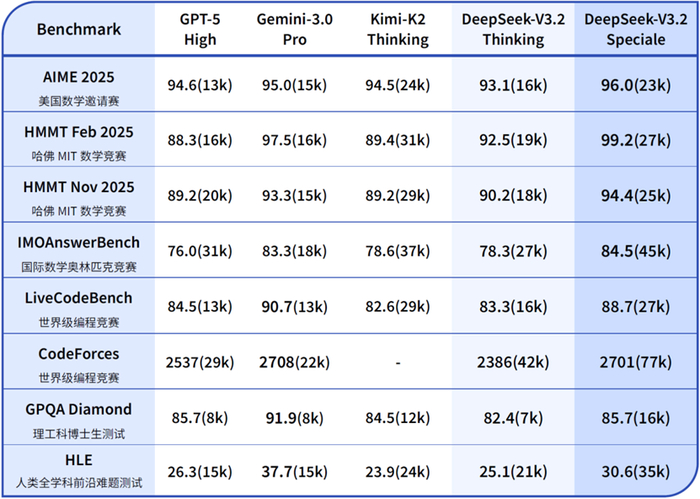
她自己介绍说,DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用Agent任务场景。在公开的推理类Benchmark测试中,DeepSeek-V3.2达到了GPT-5的水平,仅略低于Gemini-3.0-Pro;相比Kimi-K2-Thinking,V3.2的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale的目标是将开源模型的推理能力推向极致,探索模型能力的边界。V3.2-Speciale是DeepSeek-V3.2的长思考增强版,同时结合了DeepSeek-Math-V2的定理证明能力。该模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美Gemini-3.0-Pro(见表1)。
有意思的是,DeepSeek自己还介绍,在高度复杂任务上,Speciale模型大幅优于标准版本,但消耗的Tokens也显著更多,成本更高。目前,DeepSeek-V3.2-Speciale仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
不同于过往版本在思考模式下无法调用工具的局限,DeepSeek-V3.2是他们推出的首个将思考融入工具使用的模型,并且同时支持思考模式与非思考模式的工具调用。DeepSeek提出了一种大规模Agent训练数据合成方法,构造了大量「难解答,易验证」的强化学习任务(1800+环境,85,000+复杂指令),大幅提高了模型的泛化能力。
DeepSeek-V3.2模型在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。值得说明的是,V3.2并没有针对这些测试集的工具进行特殊训练,所以我们相信,V3.2在真实应用场景中能够展现出较强的泛化性。
示例为通过LobeChat使用DeepSeek-V3.2的深度思考+工具调用能力得到更加详细准确的回复
从DeepSeek这次的表现来看,我对国产大模型的信心又回来了。甚至我认为,未来大模型的技术创新,将由中国主导。美国因为算力充足,不缺“卡”,因此大模型的创新主要依靠算力。而中国因为缺乏算力,则会将创新主要集中在算法。这体现了创新的本质!原文出处:DeepSeek又回来了!国产大模型仍然能打!,感谢原作者,侵权必删!