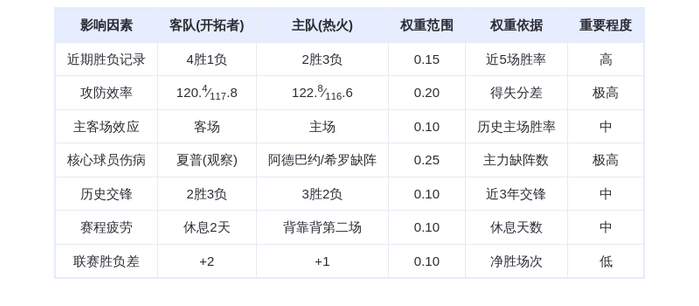
刚刚,梁文锋署名开源「记忆」模块,DeepSeek V4更细节了
:目前大语言模型主要通过混合专家(MoE)来实现稀疏化,这被称为「条件计算」。但是,现有的 Transformer 缺少原生的知识查找机制,只能被迫通过计算过程低效地模拟检索行为。
针对这一现状,DeepSeek 提出了条件记忆(conditional memory),从而与 MoE 的条件计算互补,并通过引入一个新模块 Engram 来实现
MoE 模型通过条件计算实现了模型容量的扩展,但现有的 Transformer 架构缺乏原生的知识查找原语,只能通过计算过程低效地模拟检索行为。
为了解决这一问题,DeepSeek 提出了条件记忆(conditional memory)这一与条件计算互补的稀疏化维度,并通过 Engram 模块加以实现。Engram 在经典 -gram 嵌入的基础上进行了现代化改造,使其能够以 O (1) 时间复杂度完成知识查找。
通过形式化提出稀疏性分配问题,DeepSeek 还发现了一条呈 U 型的扩展规律,用以刻画神经计算(MoE)与静态记忆(Engram)之间的最优权衡关系。
在这一规律的指导下,DeepSeek 将 Engram 扩展至 270 亿参数规模,并在严格等参数量、等 FLOPs 的条件下,其整体性能显著优于纯 MoE 基线模型
尤为值得注意的是,尽管记忆模块本身主要被用于提升知识检索能力(如 MMLU 提升 +3.4、CMMLU 提升 +4.0),但 DeepSeek 观察到其在通用推理能力(如 BBH 提升 +5.0、ARC-Challenge 提升 +3.7)以及代码与数学推理任务(HumanEval 提升 +3.0、MATH 提升 +2.4)上带来了更为显著的增益。
进一步的分析表明,Engram 能够将静态知识的重建负担从模型的浅层中剥离出来,从而有效加深网络用于复杂推理的有效深度。此外,通过将局部依赖关系交由查表机制处理,Engram 释放了注意力机制的容量,使其能够更专注于全局上下文建模,从而显著提升了长上下文检索能力(例如 Multi-Query NIAH 的准确率从 84.2 提升至 97.0)。
最后,Engram 在系统层面同样展现出基础设施感知的高效性:其确定性的寻址方式支持在运行时从主机内存进行预取,几乎不会带来额外的性能开销。
Engram 架构如下,其设计目标是在结构上将静态模式存储与动态计算过程从 Transformer 主干网络中分离出来,从而对其进行增强。该模块对序列中每一个位置依次执行两个功能阶段:检索与融合。
在运行过程中,DeepSeek 首先对当前位置的后缀 N-gram 进行提取与压缩,并通过哈希机制以确定性的方式检索对应的静态嵌入向量。随后,这些被检索到的嵌入会在当前隐藏状态的调制下进行动态调整,并进一步通过一个轻量级卷积操作加以精炼。最后,Engram 与多分支架构进行集成。
这一阶段的目标是将局部上下文映射到静态记忆条目,这一过程主要包括分词器压缩以及通过确定性哈希机制来检索对应的嵌入表示。
分词器压缩:为了最大化记忆单元的语义密度,DeepSeek 引入了一层词表投影(vocabulary projection)。为此,他们预先设计了一个映射函数,其将原始 token ID 映射为基于文本规范化等价关系(例如使用 NFKC 规范化、统一大小写等)得到的规范化标识符(canonical identifiers)。在实际应用中,对于一个规模为 128k 的分词器,该过程能够将有效词表规模缩减约 23%(详见附录 C)。
多头哈希:直接对所有可能的 N-gram 组合空间进行参数化在计算和存储上都是不可行的。借鉴 Tito Svenstrup 等(2017)的工作,DeepSeek 采用了一种基于哈希的近似方法。为了降低哈希冲突的影响,对于每一种 N-gram 阶数 n,引入 K 个相互独立的哈希头。
前一阶段通过哈希 -gram 从条件记忆中检索得到的嵌入向量,本质上提供的是一种与具体语境无关的静态先验信息。然而,正因为其静态属性,这些嵌入缺乏对当前上下文的自适应能力,并且在实际应用中可能受到哈希冲突或词项多义性带来的噪声干扰。
为此,DeepSeek 在检索之后引入了一种上下文感知的门控机制,其设计灵感来源于注意力机制。
在带有记忆机制的模型中,规模扩展往往受到 GPU 高带宽显存(HBM)容量有限的制约。然而,Engram 所采用的确定性检索机制天然支持将参数存储与计算资源进行解耦。不同于 MoE 依赖运行时隐藏状态进行动态路由,Engram 的检索索引完全由输入 token 序列决定。这种可预测性使得针对训练与推理阶段的专门优化策略成为可能,如图 2 所示。
在训练阶段,为容纳大规模嵌入表,DeepSeek 采用标准的模型并行方案,将嵌入表分片分布在多张 GPU 上。在前向传播过程中,通过 All-to-All 通信原语收集被激活的嵌入行;在反向传播阶段,则将对应梯度分发回各个分片,从而使总可用记忆容量能够随加速器数量线性扩展。
在推理阶段,这种确定性特性进一步支持一种预取–重叠(prefetch-and-overlap)策略。由于在前向计算开始之前即可确定所需访问的记忆索引,系统能够通过 PCIe 从容量充足的主机内存中异步地预取嵌入向量。为有效掩蔽通信带来的延迟,Engram 模块被放置在主干网络中的特定层级,利用其前序 Transformer 层的计算作为缓冲,从而避免 GPU 计算停顿。
这也要求一种硬件 — 算法协同设计(hardware–algorithm co-design):一方面deepseek,将 Engram 放置得更深可以拉长用于隐藏通信延迟的计算窗口;另一方面,从建模效果来看,较早地介入以卸载局部模式的重建更为有利。因此,Engram 的最优插入位置必须同时满足建模性能与系统时延两方面的约束。
此外,自然语言中的 -gram 天然遵循 Zipfian 分布,即少量高频模式贡献了绝大多数的记忆访问。这一统计特性启发研究者可以构建一种多级缓存层次结构(Multi-Level Cache Hierarchy):将高频访问的嵌入缓存于更快的存储介质中(如 GPU HBM 或主机 DRAM),而将大量低频的长尾模式存放在容量更大但速度较慢的存储介质中(如 NVMe SSD)。这种分层设计使 Engram 能够扩展到极大规模的记忆容量,同时对有效访问延迟的影响保持在最低水平。
作为「条件记忆」的一种具体实现,Engram 在结构上与 MoE 专家提供的「条件计算」形成了互补。本节旨在探究这种二元特性(Duality)的扩展属性,以及如何最优地分配稀疏容量。
首先来看MoE 与 Engram 之间的最优分配比例。在计算匹配公式时,DeepSeek 使用以下三个参数度量来分析这个权衡:
其次是「在无限内存模式下的 Engram」。在固定参数预算下优化分配之外,DeepSeek 探索了互补的设置:激进的内存扩展。这个研究的动机来自于 Engram 独特的能力,能够将存储与计算解耦。
下图 3(左)揭示了验证损失与分配比例 之间一致的 U 形关系。值得注意的是,即使 MoE 分配减少到仅 ≈ 40%(即 5.7B 模型为 46 个专家,9.9B 模型为 43 个专家),Engram 模型仍然达到了与纯 MoE 基准( = 100%)相当的性能。
此外,纯 MoE 基准证明是次优的:将大约 20%-25% 的稀疏参数预算重新分配给 Engram 获得最佳性能。定量分析中,在 10B 范围内( = 6 × 10²⁰),验证损失从 1.7248( = 100%)改善到 1.7109,接近 ≈ 80% 时的最优值(Δ = 0.0139)。值得注意的是,这一最优点的位置在不同的范围内稳定( ≈ 75%-80%),表明在固定稀疏性下,各个规模之间有一个稳健的分配偏好。这一观察到的 U 形确认了两种模块之间的结构互补性。
图 3(右)展示了增加内存槽数量会显著改善验证损失,并且这一改进在整个范围内持续稳定。该曲线遵循严格的幂律(在对数空间中线性),这表明 Engram 提供了一个可预测的扩展旋钮:更大的内存在不需要额外计算的情况下继续带来收益。
关键一点是,在扩展效率方面:虽然 OverEncoding 通过更大的内存表受益,但 Engram 在相同的内存预算下释放了更大的扩展潜力。
结合分配规律来看,这些结果验证了条件记忆作为稀疏容量的独立、可扩展轴的作用,它补充了 MoE 的条件计算
通过提出的 Engram 架构以及经验推导出的分配法则,DeepSeek 将 Engram 扩展至数十亿参数规模,以验证其在真实语言模型预训练中的有效性。
所有模型均采用完全相同的数据训练流程(相同的 token 预算及顺序),且在激活参数量上严格匹配。
关于实验设置,所有模型均在包含 2620 亿 token 的语料库上进行预训练,并采用了 DeepSeek-v3 的分词器,其词表大小为 128k。DeepSeek 在涵盖语言建模、知识、推理、阅读理解以及代码 / 数学的多样化基准测试集上对模型进行评估。对于每项基准测试,均遵循标准的提示词协议和评估指标。
扩展到 Engram-40B 进一步减少了预训练损失,并提高了大多数基准测试的性能。尽管它尚未在每个任务上严格超越 Engram-27B,但这可能是由于训练不足的结果。此外,Engram-40B 与基准模型之间的训练损失差距在训练结束时继续扩大,表明扩展的内存容量尚未在当前的 token 预算内完全饱和。
接下来是长上下文训练。通过将局部依赖建模卸载至静态查找,Engram 架构为处理全局上下文保留了宝贵的注意力容量。DeepSeek 通过进行长文本扩展训练,对这一结构性优势进行了实验验证。通过采用严密的评估协议,将架构设计带来的贡献与基础模型本身的能力剥离开来,证明了 Engram 在长程检索和推理任务中带来了显著的性能增益。
DeepSeek 首先解耦基础模型能力与架构设计之间的影响,其次进行受控对照分析,结果如下表 2 所示,主要得出了以下两个结论:
虽然注意力机制和位置编码为上下文处理提供了结构基础,但实验结果表明,长文本性能并非仅由架构先验决定。通过观察 Engram 的演进轨迹(从 41k 步到 50k 步),即使在控制相同模型架构和固定长文本扩展阶段计算预算的前提下,长文本性能仍随预训练进程单调提升。这表明长文本性能与基础模型的通用建模能力存在内在耦合。因此,严谨的架构对比必须通过对齐「基础模型损失(Loss)」而非仅仅对齐「训练步数」来控制这一混淆变量。
基于上述原则,DeepSeek 将 Engram 与 MoE 基准模型进行了对比测试。在控制基础能力的前提下,Engram 模块的效率增益变得十分显著:
最后,下图 4 是对表示对齐与收敛速度的分析。(a) 基于 LogitLens 的逐层 KL 散度分析。在模型浅层,KL 散度持续保持在较低水平,这表明 Engram 加速了预测的收敛。(b-c) 为基于 CKA 计算的相似度热力图。高相似度对角线显著的向上偏移表明,Engram 的浅层在功能上等效于 MoE 模型的深层,从而有效地增加了模型的深度。原文出处:刚刚,梁文锋署名开源「记忆」模块,DeepSeek V4更细节了,感谢原作者,侵权必删!