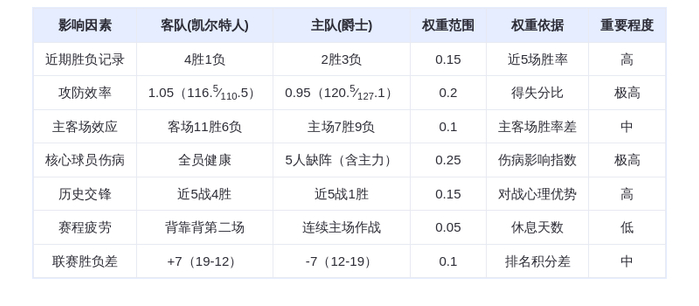
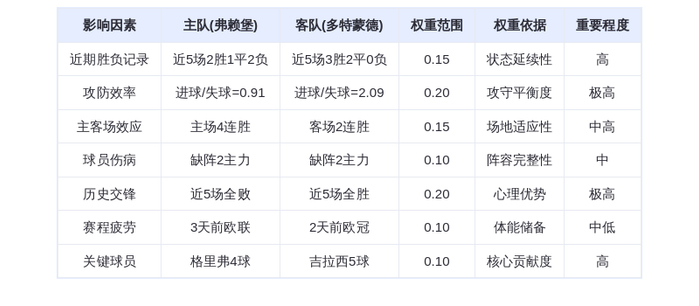
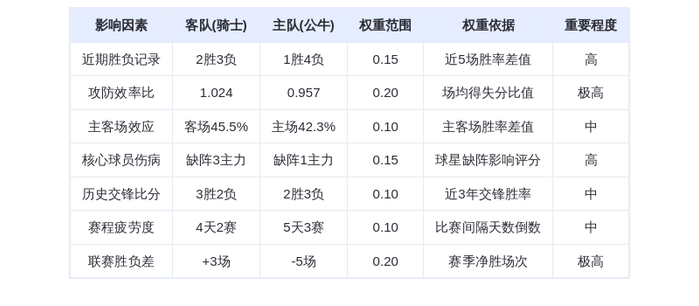
炸了!Claude深夜怒撕DeepSeek、月之暗面、MiniMax,1600万
其技术原理一点都不复杂,说白了就是给超级大模型减减负、传本事,让小模型也能有大本事,还不费资源。
咱们先说说为啥要做这件事,现在很多超级大模型,比如那些能写文章、会聊天、懂画画的,参数有几千亿甚至上万亿,就像一个学识渊博但体型笨重的老师,虽然啥都懂,但跑起来特别慢。
可我们平时用的小程序、手机APP里的智能功能deepseek,不需要这么笨重的“老师”,只需要一个小巧、反应快,还能解决问题的小徒弟。
这时候蒸馏就派上用场了,它核心就是让这个大模型当老师,把自己的本事手把手教给小模型,不用小模型从头慢慢学,省时间还能保效果。
就是先让大模型去处理大量的问题,不管是聊天、答题还是分析内容,都把它的思考逻辑、判断方式还有最终的结果,一一记录下来,相当于老师把自己毕生所学的经验和技巧,都整理成了最简单易懂的笔记。
然后再让小模型拿着这份笔记去学习,不用再去啃海量的原始数据,只需要吃透老师总结好的精华,慢慢模仿老师的思路,直到小模型处理问题的效果,无限接近大模型,但体型却小了几十倍甚至上百倍。
这样一来,小模型就能轻松装在手机、普通电脑里,运行起来飞快,成本也低了很多,平时我们用手机聊天、查资料,背后可能就是经过蒸馏的小模型在工作,既好用又不卡顿,这就是大模型蒸馏最实在的作用。
目前,关于Anthropic的指责传闻尚未得到官方证实,但它折射出的是AI行业日益激烈的竞争态势。
一方面,模型开发者投入巨资,自然希望保护核心竞争力;另一方面,技术普惠、降低使用门槛又是行业发展的必然趋势。
正如网友所言,如何界定数据使用的边界,如何平衡版权保护与技术创新,或许是接下来整个行业需要共同面对的课题。原文出处:炸了!Claude深夜怒撕DeepSeek、月之暗面、MiniMax,1600万次交互引争议,感谢原作者,侵权必删!