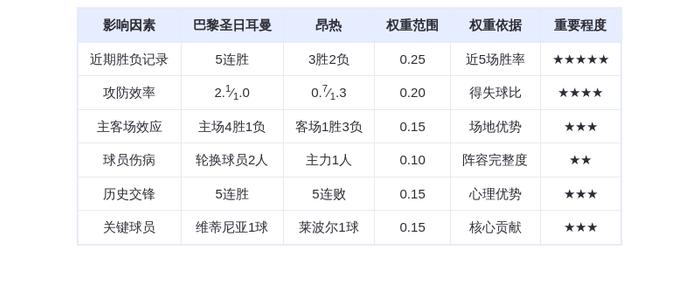
DeepSeek 的“罪与罚”
一份措辞严厉的调查报告,将矛头直指中国三家头部AI公司——深度求索( DeepSeek )、月之暗面( Moonshot )与稀宇科技( MiniMax ),指控其对旗舰模型 Claude 发动了“工业化规模”的模型蒸馏攻击。
这并非中国 AI 企业首次因蒸馏陷入争议。就在两周前, OpenAI 刚刚向美国国会提交内部备忘录,指控 DeepSeek 绕过安全防护对 GPT 系列实施蒸馏。
而这一次, Anthropic 抛出了更详尽的数据:约 2.4 万个虚假账户、超过 1600 万次交互、一套名为“九头蛇集群”的分布式架构,将恶意流量伪装成正常请求,系统性地提取Claude的推理能力、工具调用与编程数据。
然而,这份指控并未收获行业一致支持。 xAI 创始人埃隆·马斯克第一时间在 X 平台嘲讽:“他们怎么敢偷 Anthropic 从人类程序员那里偷来的东西?”
这一反击精准戳中了 Anthropic 软肋。就在 2025 年 9 月,该公司刚刚以 15 亿美元天价和解了一起盗版书籍诉讼,被发现从盗版网站下载了超过 700 万本受版权保护的书籍用于训练 Claude 。
硅谷著名评论人格尔盖伊·奥罗斯的质问直击要害:“ Anthropic 无权‘两头占便宜’, Claude 的成功本身就建立在未经许可使用受版权保护内容的基础上,如今却对同类技术的使用大加指责,难以自圆其说。”
知识蒸馏( Knowledge Distillation )是机器学习领域一项成熟且普遍的技术,核心思路是用一个强大的“教师模型”的输出来训练一个较小的“学生模型”,使其在参数规模更小、运行成本更低的情况下复现教师模型的核心能力。
Anthropic 自己在博文中也承认:“前沿 AI 实验室会定期蒸馏自己的模型,为客户提供更小、更便宜的版本。”
Anthropic 的指控核心在于,三家公司通过“虚假账户+代理服务”绕过了地区访问限制,以欺诈手段大规模提取 Claude 的输出用于训练竞品。
从商业合同的角度看,这确实违反了 Anthropic 的服务条款——几乎所有 AI 公司的 ToS 中都明确禁止使用其服务来训练或开发“与它竞争”的 AI 模型。
美国版权局 2025 年 1 月已确认,版权保护要求人类作者身份,“仅提供提示词不使输出受版权保护”。
这意味着, AI 模型的输出本身在美国法律框架下并不享有版权。即便蒸馏行为被坐实,它在法律性质上更接近合同违约,而非知识产权盗窃。
行业内部也存在认知分裂。多位开发者指出,用竞争对手的 API 输出来训练自己的模型,在行业内接近于“公开的秘密”。这并非 Anthropic 独有的遭遇,而是整个行业面临的灰色地带。
Anthropic 在博文中完成了一次精妙的叙事偷换:它将本质上的合同违约行为,重新包装成了“蒸馏攻击”,并将一个中性的技术术语与“国家安全”“生物武器”“出口管制”等关键词绑定。
有观察者一针见血地指出:“ Anthropic 正在从真实的技术事件中,蒸馏出一套服务于自身政治生存的叙事。”
更值得玩味的是事件的时间背景。 Anthropic 发布指控时,正处于与五角大楼的合作谈判僵局中,面临失去 2 亿美元国防合同的风险,而竞争对手 xAI 刚与五角大楼签署合作协议。将中国企业列为指控对象,实则是 Anthropic 向美国政府表忠的战略表态,通过渲染 中国 AI 威胁论 强化自身国家安全价值。
对于 DeepSeek 而言,这并非首次遭遇此类指控,此前 OpenAI 就曾向美国国会提交备忘录,指责其通过混淆手段蒸馏 GPT 系列模型,但 DeepSeek 始终强调自身优势源于架构创新而非模仿输出。
截至目前,DeepSeek 等三家企业均未对指控作出官方回应,这场争议已从技术合规问题,演变为全球 AI 行业话语权争夺的缩影。
但细看数据会发现一个有趣的细节:三家公司中, MiniMax 的交互次数超过 1300 万,月之暗面超过 340 万,而 DeepSeek 只有约 15 万,占比不到 1% 。
Anthropic 之所以把 DeepSeek 放在标题第一位,很大程度上是因为这个名字在华盛顿的“知名度”。自 2025 年初以来,它已成为美国 AI 政策辩论中最具标志性的中国符号。
在高端芯片出口受限、算力资源紧张的背景下, DeepSeek 确实做出了一些让人印象深刻的成果。
2025 年初发布的 R1 模型,训练成本据称只有约 560 万美元,却在多项推理测试中比肩 OpenAI 的 o1 。这种“少花钱办大事”的能力,让它在全球开发者社区赢得了不少口碑。
一位国内智能体开发者这样评价:“ DeepSeek 对社区最大的贡献,就是把 Token 的成本打下来,让更多开发者能接触 AI 开发。如果都学海外巨头烧算力,这种低成本时代将一去不复返。”
Hugging Face 在“ DeepSeek 时刻一周年”的文章中也承认, R1 降低了三重壁垒:技术壁垒(将高级推理能力转化为可复用的工程资产)、采用壁垒(开源许可让部署变得简单)、心理壁垒(证明中国团队也能定义技术范式)。
围绕 DeepSeek 的争议从未停歇。就在本月初, OpenAI 刚向美国国会提交备忘录,指控 DeepSeek 绕过安全防护对 GPT 系列实施蒸馏。
尽管 DeepSeek 方面反问“如果真是偷的,上哪儿偷去?”,并强调自身优势源于 GRPO 强化学习和 MoE 稀疏专家系统等架构创新,但这种自辩在舆论场上的说服力有限。
在开源社区,它虽然开放了模型权重和各种工具库,但最关键的数据来源始终处于黑箱状态。 Artificial Analysis 的数据显示,目前全球开放程度排名前三的模型分别来自英伟达、 Allen Institute 和阿联酋的 MBZUAI , DeepSeek 并未上榜。
这种“半开放”状态,让它始终无法摆脱外界的质疑:如果真的是靠架构创新做到的,为什么不公开数据自证清白?
虽然 R1 的训练成本号称 560 万美元,但这只是单次训练的费用。背后的研发投入、试错成本、算力采购,都由其母公司幻方量化承担——而幻方是国内顶尖的量化基金, 2025 年以 53% 的回报率赚了超 7 亿美元利润。
换句话说, DeepSeek 的“低成本”,是建立在母公司“高投入”基础上的。如果没有这座“印钞机”持续输血,所谓的“性价比优势”还能维持多久?
过去一年,中国 AI 头部企业逐渐走出了差异化的路线。智谱选择的是“智能体工程化”方向,更关注模型在实际任务中的可靠性和落地能力;月之暗面则走“ C 端投流”路线,用重金换用户心智; MiniMax 押注“轻量级效率”,用小参数模型切入编程赛道。
相比之下, DeepSeek 的定位最为特殊。它既不做投流抢 C 端——创始人梁文锋曾表示, C 端应用更像是“技术展示厅”和“数据采集器”;也不做垂直场景深耕——团队始终将重心放在底层模型的迭代上。
DeepSeek 选择把自己定位为“开源基建的提供者”。根据 OpenRouter 统计, DeepSeek-V3 和 R1 的 Token 吞吐量一度占所有开源模型的一半以上。当全球开发者在做蒸馏、微调、魔改时,都将 DeepSeek 作为第一梯队选择。
但这种“基建”定位,也意味着它离钱最远。当同行们已经开始通过 API 服务变现、探索付费订阅时, DeepSeek 至今没有清晰的商业模式deepseek。而在算力资源普遍紧张的行业背景下,这种状态能持续多久,是一个需要回答的问题。
它们相信,更大的模型、更多的数据、更长的训练时间,最终会带来质的飞跃。这是一种“力大砖飞”的逻辑,只要算力堆得足够多,总能砸出突破。
即将发布的V4据称在编程能力上可以比肩 Claude ,而成本只有后者的几十分之一。摩根士丹利的报告中有句话被反复引用:“ DeepSeek 正在证明, AI 能力的下一次飞跃可能不是来自更多的 GPU ,而是来自学会如何在约束条件下思考。”
这种路径让 DeepSeek 在全球开发者社区赢得了不少拥趸,英伟达 CEO 黄仁勋也评价其为“让整个世界惊讶的开源模型代表”。
在多模态领域,它的布局明显滞后——当智谱、阿里、腾讯纷纷发力视觉语言联合理解,当视频生成、语音合成赛道争夺“下一个 DeepSeek 时刻”, DeepSeek 仍将重心聚焦在纯文本和代码能力上。
一方面,它让团队可以不被资本裹挟、专注于技术理想;另一方面,没有自我造血能力意味着持续的研发投入必须依赖母公司幻方量化的输血。
2025 年,幻方以 53% 的回报率赚了超过 7 亿美元利润,这为 DeepSeek 提供了充足的弹药。可一旦幻方业绩波动,或外部环境变化,这种“自由人”状态将面临严峻考验。
回看 Anthropic 的蒸馏指控,一个悖论浮出水面: DeepSeek 被指控的“罪”,恰恰是西方巨头最擅长的“术”。
当 Anthropic 一边用盗版书籍蒸馏 Claude ,一边指责他人蒸馏自己的输出;当 OpenAI 一边靠每月 20 美元订阅费构筑商业模式,一边警惕开源模型侵蚀市场份额。
剥离舆论迷雾, DeepSeek 的真正启示在于:在算力封锁的硬约束下,中国 AI 走出了一条独特的突围路径。
比蒸馏争议更重要的,或许是找到一条既能在技术上“并跑”、又能在规则上“对话”的可持续发展之路。
DeepSeek 等中国企业值得被赞赏,也值得被审视;它们正在改写规则,也必须面对规则的拷问。
特别声明:以上文章内容仅代表作者本人观点,不代表新浪网观点或立场。如有关于作品内容、版权或其它问题请于作品发表后的30日内与新浪网联系。
美以对伊战争11天,伊朗逮捕120余名内鬼,美军7死140伤,以军打死1900名伊士兵和指挥官,最新动态汇总
伊朗:发射“加德尔”“法塔赫”等多型导弹,动用“海巴尔”高超音速导弹,军事行动进入全新阶段
“中方是否考虑要求美国停战并恢复对话”,外交部回应:冲突升级不符合任何一方利益,中方将继续同有关各方保持沟通、加强斡旋原文出处:DeepSeek 的“罪与罚”,感谢原作者,侵权必删!